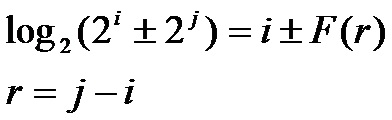The ELM belongs to a category of microprocessors known as 'digital signal processors': devices intended for fast mathematical processing which find use in a great variety of applications. Because they are often employed in battery-operated equipment, it is important that they have low power consumption. They typically work at around a tenth of the clock frequency of general-purpose microprocessors, but can often offer better performance in mathematical processing because of their specialised design.
The developers
The ELM project originated in Dr Nick Coleman's research at Newcastle University, and was then undertaken with around 1m Euros funding from the Long-Term Research sector of the European Stategic Programme for Research in Information Technology (EPSRIT). Partners in the project were the Institute of Information Theory and Automation at the Czech Academy of Sciences, Philips Research, Eindhoven, University College Dublin, and Massana Ltd, Dublin. Chips were fabricated at Philips Semiconductors, Nijmegen.
The results
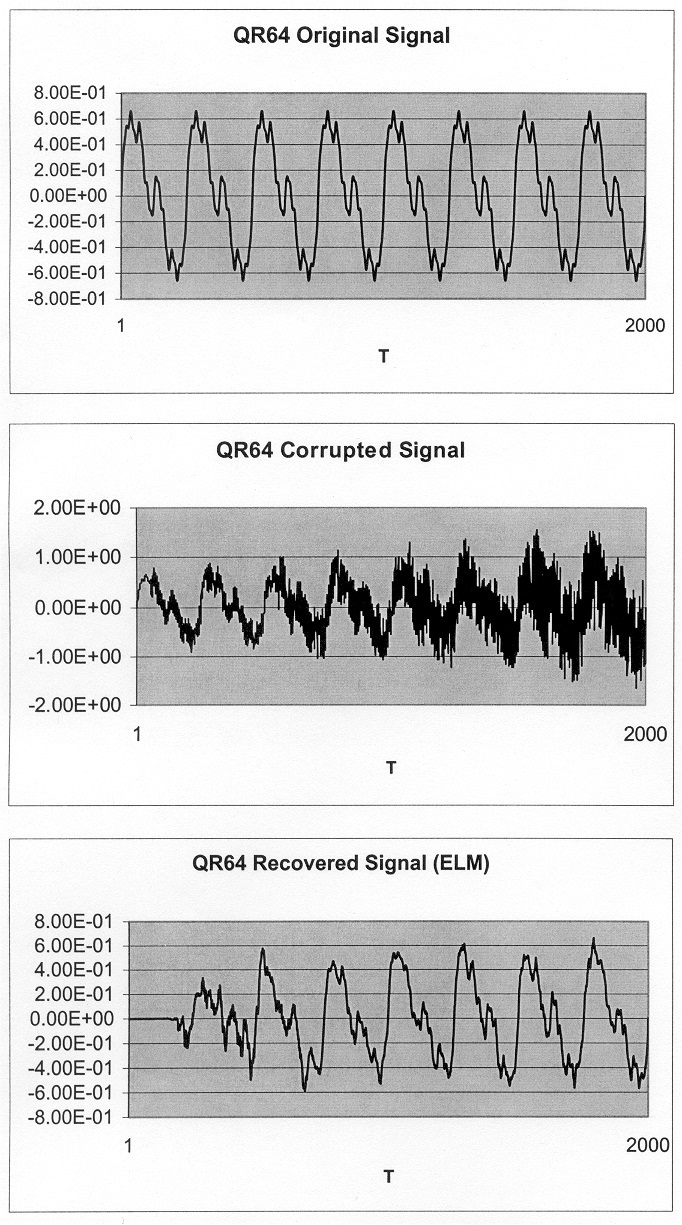
Following the original development work, a suite of industrial-scale programmes was developed to prove that the device actually worked in practice. It was also essential to show that, by using the logarithmic arithmetic system, the device could outperform a conventional microprocessor based on floating-point arithmetic. The same programmes were therefore deployed on a state-of-the-art industry-standard floating-point device, the Texas Instruments TMS320C67, and a direct comparison made between the two. The ELM delivered significantly faster execution and more accurate results. Some highlights are presented below; for full details please see 'IEEE Transactions on Computers', April 2008.
Although the LNS arithmetic circuits were faster and more accurate than the equivalent floating-point versions, one remaining problem was that they were physically larger. Continuing theoretical work has demonstrated that the transform algebra can be applied recursively. Whereas the first-order application, as described above, yielded a dramatic reduction in circuit size from a purely interpolated solution, this second-order application delivers a further large reduction in that. As we show in 'IEEE Transactions on Computers', January 2016, an LNS arithmetic unit may now be constructed with a silicon footprint similar to that of a floating-point unit. Furthermore, the lookup tables are now small enough to allow their implementation in synthesised logic, rather than, as previously, as read-only memories. This results in further gains in speed.